The Hidden Cost of Dirty Data and Why AI Data Quality Must Come First

Artificial Intelligence has transformed from a phenomenon to a practical implementation, accelerating business operations at a lower cost and with less manual work. Yet, the gap between ambition and execution has never been wider.
Gartner predicts that by the end of 2025, 30% of Generative AI projects will be abandoned after the POC phase. Why? Most often due to poor AI data quality, weak risk controls, escalating costs, or a lack of clear business value.
The numbers tell a sobering story: according to IBM’s recent CEO survey, only 25% of AI initiatives have delivered expected ROI over the last few years, and only 16% have scaled enterprise-wide.
Almost every company is ambitious to incorporate AI into its operations, but enthusiasm alone isn’t enough. Before scaling and expecting the best ROI, organizations need to get the fundamentals, including ensuring AI data quality, addressing trust and transparency issues, and putting the right infrastructure in place.

Issues Associated with Poor AI Data Quality: The Silent Killer of AI ROI
Remember “Garbage In = Garbage Out”
LLMs take your data and train the respective model to deliver output. Hence, you need to be cautious while training your AI models. Poor AI data quality manifests in multiple dimensions that systematically undermine AI performance.
Freshness issues occur when data becomes stale, causing models to make decisions based on outdated information. Completeness gaps leave critical fields unpopulated, forcing models to operate with partial visibility. Consistency problems arise when the same entity appears differently across systems; a customer record with varying spellings or addresses creates confusion rather than clarity.
Correctness defects represent perhaps the most dangerous category: fundamentally wrong data that looks plausible but leads to catastrophic decisions. When Unity Software ingested bad data from a large customer in 2022, it resulted in a $110 million revenue loss and $4.2 billion market cap evaporation.
Beyond these technical dimensions, organizations face fragmentation, information siloed across disconnected systems, and context gaps where data lacks surrounding details needed to make sense of it. Numbers without units, transactions without timestamps, and customer records without channel attribution all represent context failures that AI models cannot overcome through algorithmic sophistication alone.
Consequences of Poor Data Quality: The Economic Drag That Compounds
Poor AI data quality costs organizations an average of $12.9 million annually, but this figure barely scratches the surface. A recent MIT study reveals that 95% of enterprise AI solutions fail, with 85% of AI project failures attributed to data readiness issues. The true economic impact manifests across multiple dimensions that create a compounding effect.
The 1x10x100 rule underscores this escalation: addressing a data quality issue at the point of entry costs 1x the original amount, but if it propagates undetected within the system, costs increase to 10x. When poor data quality reaches the decision-making stage, costs skyrocket to 100x due to operational disruptions, lost opportunities, and customer dissatisfaction.
Organizations waste resources on endless cycles of model retraining that never quite perform as expected. AI teams burn hours investigating model degradation only to discover the root cause was schema drift in upstream data feeds.
Learn more about AI model drift and its impact on the overall outcome.
Support teams field customer complaints about inaccurate recommendations or predictions. Compliance teams scramble to explain algorithmic decisions made on faulty data. Each consequence creates its own cost stream: inflated labeling spend, unnecessary infrastructure waste, delayed time-to-market, and mounting compliance exposure.
Reducing Risks with Better Data Management: The Governance Imperative
Organizations with mature data and AI governance frameworks experience improvement in financial performance. The path forward requires implementing data contracts and data quality SLAs that prevent bad data from entering AI pipelines in the first place.
Data contracts function like APIs for data: they specify schema (field types, nullability), ranges and validation rules, null policies, freshness requirements, PII handling protocols, and ownership with clear accountability. Strong contracts answer the critical questions: what fields are required, what each field means, what validation to run, and who owns fixes when violations occur.
Data quality SLAs quantify the level of service data must provide, with automated checks that block bad data before inference or training. Core SLA metrics include accuracy (how correct the data is), completeness (whether all fields are filled), consistency (whether data aligns across systems and over time), timeliness (age of included data), uniqueness (measuring duplicate records), and validity (how well data conforms to desired formatting).
Organizations should implement a Data Debt Ledger, a one-page inventory listing each critical system, its defect type, business impact, assigned owner, and the “interest rate” showing how quickly the problem compounds. This ledger transforms abstract AI data quality into actionable investment priorities that CFOs can understand and fund.
The Problem with Data Quality & AI: Why Models Can't Compensate
The relationship between data quality and AI performance is direct and uncompromisable. AI effectiveness depends primarily on data quality, and organizations consistently struggle with data discovery, access, quality, structure, readiness, security, and governance.
Half of surveyed CEOs acknowledge that the pace of recent investments has left their organization with disconnected, piecemeal technology. This fragmentation creates AI data quality nightmares that no model architecture can overcome.
– Karthick V
Designing an Experiment: How Much Bad Data Can AI Handle?
Organizations should conduct controlled experiments to understand their AI systems’ tolerance for data quality degradation. Start by establishing baseline model performance on clean, validated data. Then systematically introduce specific data quality defects, missing values, outdated records, duplicate entries, or incorrect labels, and measure performance degradation at each threshold.
This experimental approach reveals critical breaking points: the percentage of missing values that causes precision to drop below acceptable levels, the staleness threshold where predictions become unreliable, or the duplication rate that triggers significant recall degradation.
Armed with these thresholds, organizations can set AI data quality SLAs that maintain model performance within acceptable ranges.
Airbnb’s “Data University” initiative enhanced data literacy, resulting in a 15% rise in weekly active users of internal data science tools, from 30% to 45%.
Managing Data Quality for AI: Four Critical Practices
1. Know Your Data
Implement comprehensive data profiling across all sources feeding AI systems. Measure completeness percentages, identify drift patterns, document lineage, and establish ownership. Organizations cannot govern what they don’t measure.
2. Set Realistic Targets
Not all data needs to be perfect, prioritize based on business impact. Critical decision-making systems require higher data quality standards than exploratory analytics. Set tiered SLAs that align quality investment with business value.
3. Keep Track of Incidents
Create a systematic process for logging data quality incidents, their root causes, time-to-resolution, and business impact. This incident tracking creates organizational learning and identifies patterns requiring architectural changes.
4. Maintain Feedback Loops
Establish continuous monitoring that alerts data producers when downstream AI systems detect quality degradation. This creates incentives for data producers to care about data quality, fostering a culture of ownership that leads to more explainable and trustworthy data.
How to Make the Most of AI in 2025: Six Strategic Imperatives
1. Having the Right Data Foundation is Critical
Before deploying advanced models, invest in data infrastructure that ensures quality, accessibility, and governance. The 68% of CEOs who identify integrated enterprise-wide data architecture as critical for success understand this priority.
2. It's Time to Move Beyond General AI Use Cases
Focus on specific, high-value applications where data quality can be controlled and business impact measured. Generic AI experimentation without clear ROI thresholds perpetuates the 75% failure rate. [fortune]
3. Review Your AI ROI and Partner Ecosystem
Conduct rigorous assessments of which AI initiatives deliver measurable business value. Evaluate partners not just on algorithmic capabilities but on their understanding of data quality requirements and governance frameworks.
4. Be Realistic About the Risks of AI
Organizations must acknowledge that AI systems amplify whatever data quality deficiencies exist. Overfitting to synthetic patterns, privacy leakage, and spurious correlations represent real risks requiring continuous monitoring.
5. Transparency-Driven Trust
Implement explainable AI frameworks that allow stakeholders to understand how models make decisions. This transparency becomes impossible without high-quality, well-documented data lineage.
6. Data Integration
Break down silos that create fragmentation and consistency issues. Unified data architectures reduce the multiple-source conflicts that undermine AI performance.
30/60/90-Day Execution Plan for Data Quality
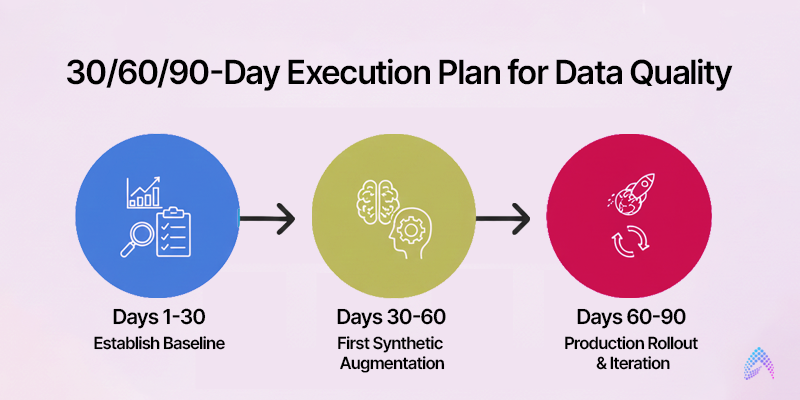
Days 1-30: Establish Baseline
Create your Data Debt Ledger, identifying the top five highest-impact data quality issues
Quantify current costs: model retrain frequency, labeling rework hours, and incident tickets attributed to data quality
Implement contracts for two critical data feeds with schema validation and automated alerts
Baseline KPIs: data freshness %, completeness %, model performance on key segments
Days 31-60: First Synthetic Augmentation
Days 61-90: Production Rollout & Iteration
Calculate ROI: cost of synthetic data generation versus baseline costs (labeling, collection, retrain cycles)
Present results to executive sponsors with business-metric focus
By day 90, you should have proof points: one successful synthetic data use case in production, measurable cost savings, and organizational buy-in to scale governance and selective synthesis.
Significance of Synthetic Data: A Precision Instrument, Not a Band-Aid
Synthetic data is generated by models to augment or substitute portions of real data and offers powerful capabilities when deployed strategically. By 2024, Gartner predicted that 60% of data used for AI and analytics projects would be synthetically generated. The global synthetic data generation market is expected to grow from $351.2 million in 2023 to $2.3 billion by 2030. [ibm]
Where synthetic data shines: It addresses coverage gaps and class imbalance, generating examples of rare diseases or fraud spikes that natural data collection cannot economically capture.
It provides privacy, creating shareable datasets for vendors and partners without exposing PII. It enhances robustness through edge-case stress tests and domain shift simulations. And it serves as test data for CI/CD pipelines.
Critical limitation: Synthetic data cannot fix broken semantics, correct mislabeled ground truth, or modify the underlying causal structure. It amplifies whatever governance deficiencies already exist. Organizations must govern first, synthesize second, establishing data contracts and quality SLAs before deploying synthetic augmentation.
Healthcare Industry Example: Where Data Readiness Determines AI Success
Healthcare demonstrates both AI’s transformative potential and AI data quality’s make-or-break role. Eighty percent of healthcare leaders believe AI will transform clinical decision-making, yet only 30% of AI pilots reach production. The primary barrier? Data readiness.
Healthcare organizations face unique AI data quality challenges: fragmented electronic health records across providers, inconsistent coding standards, missing clinical context, and stringent privacy regulations that complicate data sharing. A patient’s medical history might exist in five different systems with incompatible schemas, making a comprehensive AI-driven diagnosis nearly impossible without significant data integration work.
Successful healthcare AI implementations prioritize data foundation over model sophistication. Organizations that invest in unified patient data platforms, standardized clinical vocabularies, and robust consent management see dramatically higher AI pilot-to-production conversion rates.
Synthetic data plays a crucial role here, enabling algorithm development and testing while protecting patient privacy, but only after establishing governance frameworks that ensure synthetic data maintains clinical validity.
Conclusion: Making Data Quality Your Competitive Advantage
The AI revolution won’t be won by those with the most sophisticated models; it will be won by those with the highest quality data powering those models.
Amzur Technologies understands that AI strategy consulting begins with data quality assessment, not model selection. As a trusted AI strategy consulting and implementation services provider serving organizations across the United States, Amzur helps clients build the data foundation that makes AI transformation possible.
From establishing data contracts and quality SLAs to implementing synthetic data capabilities where they deliver measurable value, Amzur’s approach prioritizes sustainable ROI over technological experimentation.
Are you still unsure about your data quality? Register for our expert-led AI workshop and get deep insights of your business data .
Frequently Asked Questions
What is AI data quality?
When should I use synthetic data?
How does RAG improve results?
Which KPIs prove improvement?
What’s the fastest way to start?

Director ATG & AI Practice






