RAG Framework Explained: Why Contextual Retrieval Beats Static Models

In 2025, Retrieval-Augmented Generation (RAG) is emerging as the most transformative method for improving the performance of large language models (LLMs). These models, such as GPT-5, have taken the world by storm with their impressive ability to generate fluent, human-like text. However, despite their powerful capabilities, plain LLMs struggle with major limitations: stale knowledge, hallucinations, and high fine-tuning costs.
Despite dramatic leaps in large-language-model (LLM) capability, a 2025 Nature study found these systems still hallucinate 1.47 % of the time, enough to inject misleading facts into clinical notes, legal briefs, or financial analyses. That tiny percentage translates into thousands of mistakes at enterprise scale, eroding trust and exposing organizations to regulatory and reputational risk. In high-stakes settings, a single hallucination can trigger patient-safety events, compliance violations, or multimillion-dollar decisions based on fiction.
Retrieval-Augmented Generation (RAG) fixes this vulnerability by pairing the LLM’s reasoning power with a real-time evidence engine. Before the model drafts an answer, RAG fetches verifiable passages from vetted databases, clinical guidelines, policy documents, or proprietary knowledge bases, and feeds them into the prompt, requiring the LLM to ground every statement in cited facts.
The result: dramatically lower hallucination rates, transparent sourcing for auditors, and AI outputs that professionals can trust when accuracy is non-negotiable.
This article will explain what RAG in AI is, how it improves LLM performance, how to implement it, and why it’s essential for the future of AI development.
What Is Retrieval-Augmented Generation in AI?
High-Level Architecture of the RAG Framework
The RAG framework is a combination of two core components:
1. Retriever
This component retrieves relevant data from a pre-built index. The data could be documents, research papers, FAQs, or even historical records stored in databases. It works by searching for the most relevant information based on a user’s query, ensuring that the data provided is highly relevant and up-to-date.
2. Generator (LLM):
Once the retriever has fetched relevant information, this is passed to the LLM, which generates a natural language response grounded in that information. Unlike traditional LLMs that generate answers based on a fixed model, RAG augments the model’s output with real-time data from the retrieval step, ensuring responses are not only fluent but accurate and factual.
This architecture is a modular approach, meaning that retrieval can be updated independently of the LLM. For instance, if the latest medical guidelines are published, the retrieval index can be refreshed without the need to retrain the entire model. This dynamic adaptation allows RAG to deliver accurate and up-to-date answers continuously.
Key takeaway:
The RAG framework doesn’t relax. It adds real-time retrieval to large language models, ensuring answers are based on the most recent and authoritative data, making them trustworthy and accurate.
RAG in AI vs. Fine-Tuning & Prompt Engineering
Prompt Engineering:
Fine-tuning prompts in LLMs allows for the manipulation of output, but it cannot address knowledge gaps. The model still depends on the training data, which becomes outdated as the world changes.
Fine-Tuning:
Involves retraining a model with new data, but it is computationally expensive and results in model bloat, which can lead to inefficiency. Fine-tuning can also lead to catastrophic forgetting, where the model forgets previously learned information while learning new data.
RAG:
RAG sidesteps these issues by separating retrieval from generation. Instead of overloading an LLM with constant retraining, RAG enhances it by using dynamic data retrieval at inference time, ensuring that models always have access to the freshest content without incurring high fine-tuning costs.
Learn more about Amzur’s proprietary 6-step AI implementation framework.
Top Limitations of Traditional LLMs
While LLMs like GPT are impressive, they have fundamental limitations that RAG directly addresses:
1. Stale Knowledge:
LLMs are trained on data that becomes outdated quickly. For instance, an LLM trained in 2021 won’t know the latest advancements in COVID-19 treatments or regulatory changes. Without continuous updates or real-time access to data, their answers will become less relevant as time passes.
2. Hallucinations
One of the primary issues with LLMs is the tendency to generate incorrect or fabricated information with high confidence. This is especially problematic in fields where accuracy is critical. Studies show that even with improved models, LLMs can still generate answers that sound correct but are completely false.
3. Context-Window Limitation
The context window for LLMs (i.e., the amount of data the model can “remember” or process at once) is limited. This poses a problem for industries that need to process large datasets or maintain long-term context across multiple interactions.
4. Costly Fine-Tuning
Fine-tuning a large model like GPT-5 on a specific dataset can cost tens of thousands of dollars in computational resources. Additionally, re-training models continuously to keep up with new data is both time-consuming and expensive.
Key takeaway:
Traditional LLMs are great at language generation but fall short in areas like knowledge freshness, factual accuracy, and scalability. The RAG framework fixes these problems by allowing LLMs to pull in real-time data from authoritative sources.
Anatomy of a Modern RAG Framework
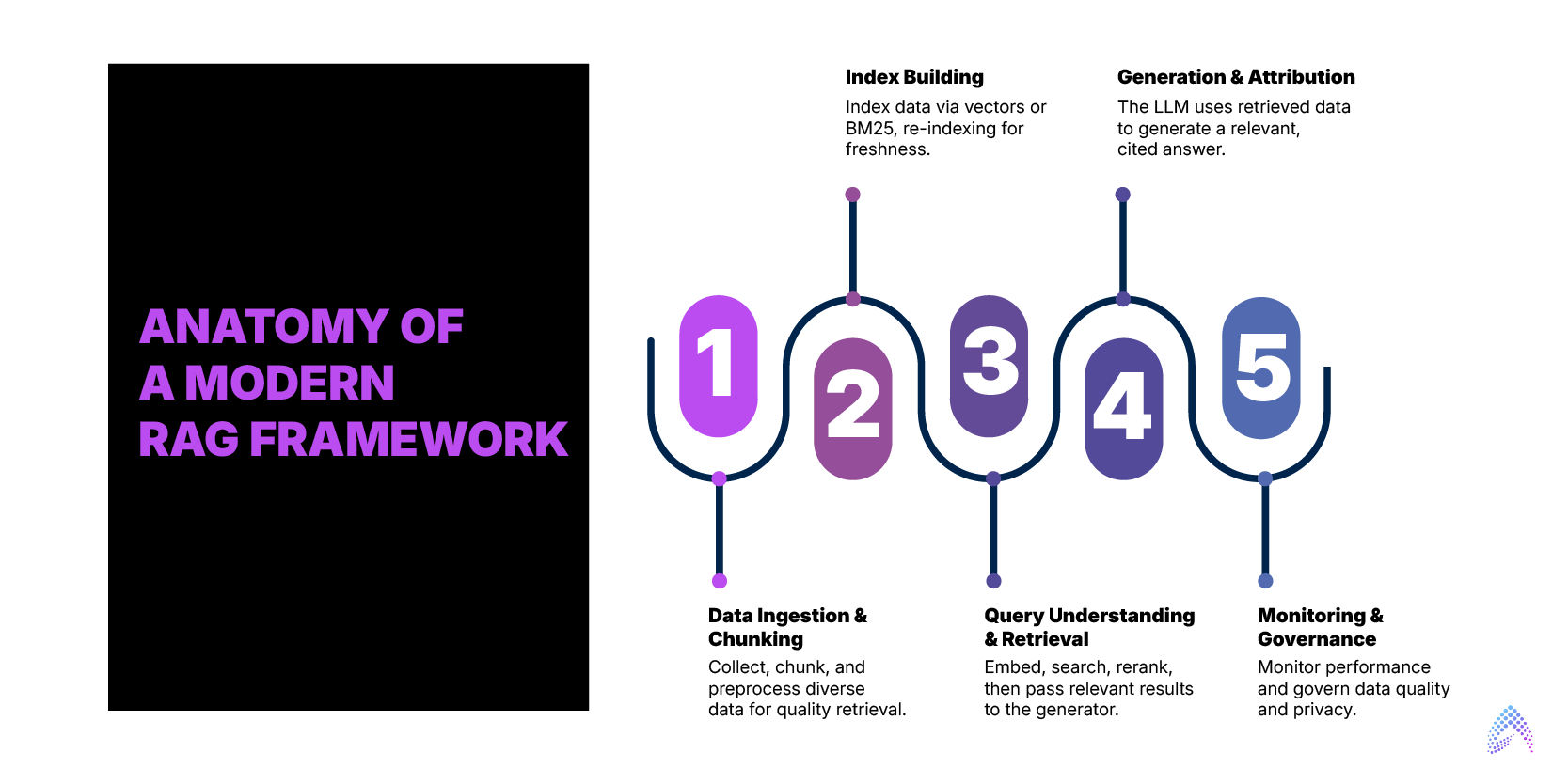
The RAG framework follows a multi-step process designed to deliver accurate, real-time results. Here’s how it works:
1. Data Ingestion & Chunking:
Collect data from various sources (databases, web pages, PDFs, etc.) and break it into small, semantically meaningful chunks (200-1,000 tokens).
Use preprocessing to ensure high-quality, consistent formatting that aids retrieval.
2. Index Building
Index the ingested data using dense vector representations (via embeddings) and/or traditional search algorithms like BM25.
Periodically re-index the data to ensure freshness. This allows the retriever to search the most up-to-date data when generating answers.
3. Query Understanding & Retrieval
Once a user submits a query, the system embeds the query and searches the indexed data for the top relevant documents or text passages.
These results are reranked for relevance, with the most useful documents being passed to the generator.
4. Generation & Attribution
The generator (LLM) uses the retrieved data, combining it with its internal model to produce a coherent, relevant response
The answer is attributed with citations or source links, ensuring transparency and trustworthiness.
5. Monitoring & Governance
Continuous monitoring tracks retrieval quality, model accuracy, and performance.
Implement governance protocols to filter out low-quality data and ensure compliance with privacy regulations, especially in sensitive sectors like healthcare and finance.
Key takeaway:
The RAG framework is a modular, dynamic approach that enables continuous access to fresh knowledge without retraining the model, delivering accurate, citation-backed results.
How To Improve LLM Performance With RAG Framework
By adding a retrieval layer, the RAG framework addresses many of the performance limitations seen in traditional LLMs:
1. Hallucinations:
With a retrieval mechanism in place, the model is grounded in real-world documents, preventing it from fabricating facts. By always referencing external sources, RAG minimizes errors, making outputs more reliable and trustworthy.
2. Domain Accuracy
Retrieval allows the model to pull specific, up-to-date knowledge tailored to a domain. For instance, in healthcare, RAG can fetch the latest clinical guidelines, making the model more accurate when discussing recent treatments or drugs.
3. Fine-Tuning Costs
With the retrieval process updating the model’s context dynamically, there is no need for expensive fine-tuning. RAG leverages pre-existing data, reducing the need for constant retraining while still providing accurate, fresh content.
4. Explainability
With RAG’s citation functionality, users can see the exact source from which the answer was derived, enhancing transparency and trust.
Key takeaway:
The RAG framework empowers LLMs by reducing hallucinations, improving accuracy, cutting fine-tuning costs, and making the output more understandable and reliable.
How to Implement RAG in AI: 6-Step Guide
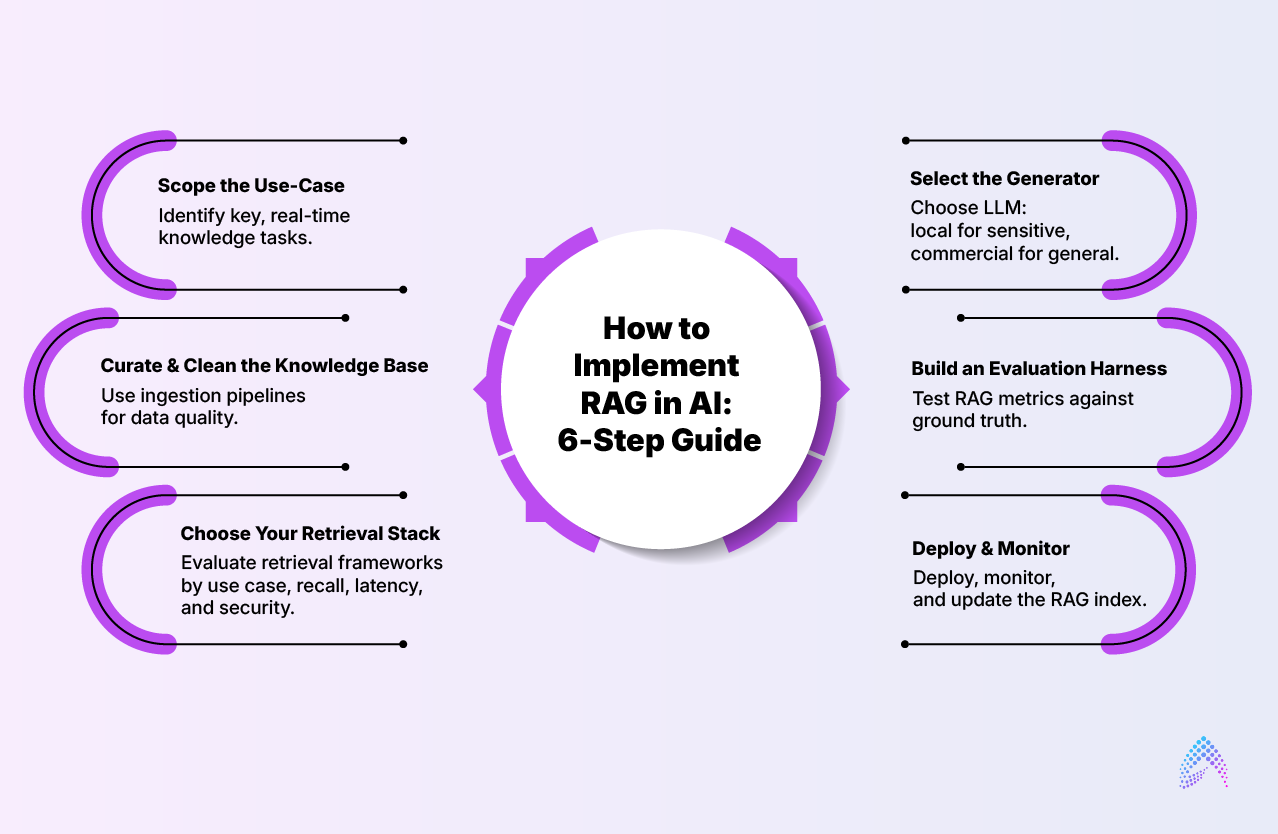
1. Scope the Use-Case:
Start by identifying high-value, knowledge-intensive tasks such as customer support, legal research, or medical decision support where real-time information retrieval is critical.
2. Curate & Clean the Knowledge Base
Ensure data is clean, structured, and consistent. Data ingestion tools should include preprocessing pipelines to handle redundancy, missing data, and poor formatting.
3. Choose Your Retrieval Stack
Select a retrieval framework based on your use case—options include open-source libraries like LangChain or LlamaIndex, or commercial services like Pinecone or Azure AI Search. Evaluate them based on your needs for recall, latency, and security.
4. Select the Generator
Choose a LLM suited for your use case. For sensitive applications, consider a local LLM, while for general tasks, commercial options like GPT-5 may suffice.
5. Build an Evaluation Harness
Create a test suite for evaluating RAG’s accuracy, latency, and relevance. Measure hallucination rates and compare model performance to ground-truth data.
6. Deploy & Monitor
Deploy your RAG-powered application via an API. Ensure that you monitor it continuously for performance, updating the retrieval index as needed to reflect new information.
Use case of RAG in Radiology
RAG (retrieval-augmented generation) strengthens imaging-result analysis by grounding an assistant’s draft impressions and recommendations in current, citable sources instead of model “memory.” At query time, it pulls the most relevant guideline snippets (e.g., ACR Manual on Contrast Media, Fleischner- or LI-RADS-style criteria) and the patient’s priors, then has the LLM synthesize a report with inline citations, cutting hallucinations and harmonizing follow-up advice.
Radiology is a perfect example where RAG offers tangible benefits. Radiologists must interpret vast amounts of medical literature, patient histories, and imaging results. A plain LLM might get overwhelmed, missing out on new medical research or failing to provide specific diagnoses. By integrating RAG, the model can access up-to-date guidelines, previous reports, and external medical research in real-time.
Beyond accuracy, RAG boosts efficiency and the clinical experience in the reading room. Because retrieval brings the right priors, labs, and policy excerpts to the cursor, radiologists spend less time hunting across PACS/EMR and more time interpreting images. [Ref]
Future Trends for the RAG Framework
Looking ahead, several emerging trends will further enhance the RAG framework:
1. Multimodal RAG
The next wave will integrate visual and text-based retrieval, enabling powerful systems for industries like pathology, autonomous driving, and industrial inspections.
2. Real-Time Indexing
As AI adapts to the needs of the modern world, the ability to index live, streaming data will become more common, allowing real-time updates for search and retrieval.
3. Agentic RAG Pipelines
AI agents that perform complex multi-step reasoning (e.g., pulling data from multiple sources, performing calculations, and generating a decision) will be powered by RAG.
4. Privacy-Preserving RAG
With increasing privacy regulations, privacy-preserving retrieval will ensure data is processed without revealing sensitive user information, making RAG models more secure and compliant.
5. Regulation-Ready Audit Trails
With the increasing use of AI in regulated industries, RAG-powered systems will need to generate audit trails to track the origin of retrieved documents and decisions.
Key takeaway:
RAG significantly improves radiology workflows by providing accurate, up-to-date context from real-time sources, allowing clinicians to make more informed, timely decisions.
Conclusion
The RAG framework is the future of scalable, accurate, and real-time AI. It solves the issues inherent in plain LLMs, including hallucinations, outdated knowledge, and high fine-tuning costs by integrating the retrieval of real-time data with the power of generative AI. Whether in healthcare, customer service, or legal research, RAG augments AI’s power, ensuring reliable, current, and contextually grounded results.
For organizations looking to scale their AI products, integrating the RAG framework will ensure accuracy, efficiency, and minimal technical debt, setting them up for long-term success in the rapidly evolving AI landscape.
Let Amzur be your AI implementation partner and build future-ready scalable solutions.
Frequently Asked Questions
What is the RAG framework?
RAG (Retrieval-Augmented Generation) pairs a retriever (that fetches relevant passages from a curated index) with a generator (LLM) that writes answers grounded in those passages, often with citations. It keeps outputs current without retraining the model.
How does the RAG framework reduce hallucinations?
By injecting verified context at inference time, the LLM is constrained to synthesize from sourced facts. Requiring citations and enforcing “answer-only-from-context” prompts materially lowers fabricated claims.
When should I use RAG vs. fine-tuning?
Use RAG when knowledge changes frequently, you need citations, or content lives in documents/wikis/policies. Use fine-tuning for style/format control or narrow tasks with stable data. Many teams start with RAG, then fine-tune lightweight models for polish.
How do we measure RAG performance?
Track retrieval precision/recall (top-k), answer faithfulness to sources, task accuracy (domain KPIs), latency/SLOs, and user feedback. Run A/B tests, keep a labeled eval set, and monitor data/model drift over time.
What about security and compliance with RAG?
Keep a vetted, access-controlled index; apply PII filters before indexing and at query time; log inputs, sources, model/version, and decisions for auditability. For sensitive workloads, prefer private indexes and least-privilege retrieval endpoints.

Director ATG & AI Practice




